MTCNN tensorflow实现
依赖环境
需要安装opencv、numpy、tqdm
1 | pip install opencv-python |
参考代码
https://github.com/LeslieZhoa/tensorflow-MTCNN
使用流程
手动下载数据,并解压到data目录
下载用于人脸检测的训练数据:WIDER_train
下载用于人脸对齐的训练数据:lfw_5590&net_7876
WIDER_train的数量标注,阈值比较宽,尽可能多的将人脸标注,甚至遮挡很多的也被标注了
- 数据预处理
- 生成tfrecords数据
- 执行训练
PNet训练步骤
使用“python gen_12net_data.py”命令,对WIDER_train下的图片进行处理,生成3种图片,大小均调整为12x12:
- 正样本,截取图片中的人脸区域,生成坐标文件,产生约40万张
- 负样本,截取图片中的非人脸区域,生成坐标文件,产生约100万张图片
- 部分样本,截图图片中包含部分人脸区域,生成坐标文件,产生约100万张图片
- 使用“python gen_landmark_aug.py 12”命令,对lfw_5590&net_7876下的图片进行处理,生成landmark图片,大小也调整为12x12,截图图片中的人脸区域,生成人脸对齐点的坐标文件,产生约17万张图片
- 使用”python gen_imglist_pnet.py“命令,从上述4种数据中按比例提取数据(步骤1中的3处数据比例为1:3:1,步骤2种的数据取全部),生成新的坐标文件
- 使用”python gen_tfrecords.py 12“命令,按照步骤3中生成的文件,提取图片,生成tfrecord数据
- 使用”python train.py 12 “命令,使用tfrecord数据进行训练
RNet训练步骤
- 使用“python gen_hard_example.py 12”命令,
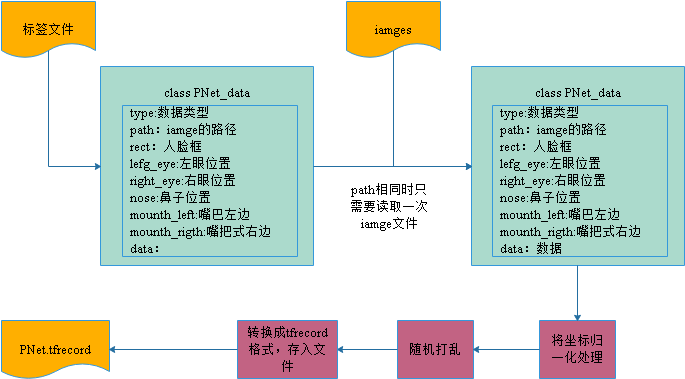
制作PNnet tfrecord文件新方法
默认的方法会产生大量的中间文件,导致大量IO操作,生成文件的速度非常慢,因此设计一种新的方法:
- 从人脸框标签(或者叫坐标)文件(wider_face_train.txt)中获取数据
- 使用随机方法,生成正样本、负样本、部分人脸样本3种数据样本,以变量的形式保存在内存中
- 从人脸对齐标签文件(trainImageList.txt)中获取数据,截取人脸,将数据追加到步骤2的变量中
- 使用前面步骤产生的类变量,从image中提取数据
- 将变量中的坐标在归一化处理
- 将变量随机打乱
将变量的数据转成tfrecord格式,存入文件